10282번: 해킹
최흉최악의 해커 yum3이 네트워크 시설의 한 컴퓨터를 해킹했다! 이제 서로에 의존하는 컴퓨터들은 점차 하나둘 전염되기 시작한다. 어떤 컴퓨터 a가 다른 컴퓨터 b에 의존한다면, b가 감염되면
www.acmicpc.net
문제 설명
다익스트라 알고리즘을 사용하는 문제입니다.

- 첫 줄의 3 3 1는 각각 컴퓨터 수(n), 의존성 수(d), 감염원번호(c)를 의미합니다.
- 두 번째 줄부터 의존성 수(d)만큼 데이터가 주어집니다.
- 각각은 a, b, s로 "b는 a에 의존하며 s초 후에 감염된다"는 의미를 가지고 있습니다.
- 감염의 시작은 c입니다.
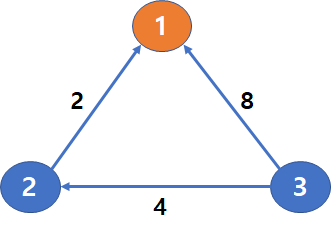
왼쪽과 같은 그림에서 감염이 일어나는 순서는 다음과 같습니다.
- 1은 감염원이므로, 0초 후에 감염이 됩니다.
- 2는 2초 후에 감염이 됩니다
- 3은 8초가 아닌 6초 후에 감염이 됩니다.
각 변수의 조건 범위는 다음과 같습니다.
(1 ≤ n ≤ 10,000, 1 ≤ d ≤ 100,000, 1 ≤ c ≤ n)
(1 ≤ a, b ≤ n, a ≠ b, 0 ≤ s ≤ 1,000)
리턴하고자 하는 답은 감염된 컴퓨터의 수와 감염되는데 걸리는 시간입니다.
알고리즘 설명
1. 다익스트라 알고리즘으로 문제를 해결하기 위해 아래와 같은 형식으로 데이터를 입력 받습니다.
이 리스트를 data라고 부르겠습니다.

- 1번 컴퓨터를 2와 3이 의존합니다. 각각은 2초와 8초 후에 감염됩니다.
- 0번 컴퓨터는 없습니다. 문제풀이 편의상 1~(N+1)의 리스트를 만들었습니다.
2. 각 노드로 갈 수 있는 최소시간을 갱신할 리스트를 만듭니다. 이 리스트를 dy라고 부르겠습니다.

- timepassed는 x초 후에 감염되는 컴퓨터(a)를 의미합니다.
- 0번 컴퓨터는 없습니다. 문제풀이. 편의상 만들었습니다.
다익스트라 알고리즘은 각 노드로 가는 최소값을 구하는 문제입니다.
각 노드는 반복적으로 실행됨으로써 최소값으로 갱신됩니다.
문제에서 주어진대로 반복의 시작점은 감염원 번호(c)인 1번 컴퓨터입니다.
따라서 1번 컴퓨터를 0으로 설정합니다.
나머지는 10,000,000으로 설정합니다.
10,000,000인 이유는 문제 조건에서 최대 컴퓨터의 개수는 10,000, 감염에 걸리는 최대 시간은 1000이라고 했습니다.
따라서 최종적으로 감염에 걸릴 수 있는 최대 시간은 10,000*1,000인 10,000,000입니다.
3. Heap 자료구조를 사용할 리스트를 만듭니다. 이 리스트를 q라고 부르겠습니다.

Heap을 위해 사용할 리스트에 (s+timePassed, a) 형태로 값을 입력받습니다.
s+timePassed는 a번 컴퓨터가 감염될 때까지 걸릴 최종 시간을 의미합니다.

예를 들어 왼쪽 그림의 경우에는,
2번 컴퓨터는 2초 후에 감염됩니다.
3번 컴퓨터는 2초 + 4초인 6초 후에 감염됩니다.
4. 반복문을 수행합니다.
(1) 1번 컴퓨터에서 감염이 시작됩니다.
(2) data의 1번 컴퓨터에 있는 (2,2), (3,8)를 모조리 꺼냅니다.
(2-1) 2번 컴퓨터의 감염시간인 2초와 dy[1]를 더한 값은 10,000,000보다 작으므로,
dy[2]를 2+dy[1]인 2로 갱신합니다.

(2-2) 최소 값을 우선으로 리턴하기 위해 q에 값을 넣습니다.

(2-3) 3번 컴퓨터의 감염시간인 8초와 dy[1]를 더한 값은 10,000,000보다 작으므로,
dy[3]을 8+dy[1]인 8로 갱신합니다.

(2-4) 힙 큐 알고리즘을 위한 q에 값을 추가합니다.

(3) q에 있는 최소시간은 2이므로, 힙 큐 알고리즘에 의해 (2,2)를 꺼냅니다.

(3-1) data[2]의 값은 (3,4)입니다. 2초 + 4초인 6초는 dy[3]인 8초보다 작으므로, dy[3]을 6초로 갱신합니다.

(3-2) q에 값을 추가합니다.

(4) q에 있는 최소시간은 6이므로 (6,3)을 꺼냅니다.

(4-1) data[3]에는 비교대상이 없으므로 dy, queue 리스트의 변화가 없습니다.
(5) q에 있는 (8,3)은 이미 dy[3]보다 크므로, 비교/갱신을 진행하지 않고 꺼냅니다.
(6) 답을 리턴합니다.
- 1000000을 제외하고 가장 큰 값은 최종 감염시간을 나타냅니다 : 6
- 1000000을 제외한 값의 개수는 감염된 컴퓨터의 수를 나타냅니다 : 3
문제풀며 작성한 구상도

문제 풀면서 작성했던 구상도입니다. 혹시 위의 설명으로 부족하신 분은 참고해서 봐주세요
코드
import sys
import heapq
# sys.stdin = open("C:/Users/JIn/PycharmProjects/coding_Test/input.txt", "rt")
numTestcase = int(input())
for _ in range(numTestcase):
n, d, c = map(int, input().split()) # n : 컴퓨터 수, d : 의존성 수, c : 감염원
data = [[] for _ in range(n+1)] # '인덱스'는 의존받는 대상(b), '값'은 [(x초 후 감염, 의존하는 대상(a))]
for _ in range(d):
a, b, s = map(int, input().split()) # 감염 방향: b -> a, s초 후 감염
data[b].append((s, a))
# 다익스트라 알고리즘
dy = [100000000] * (n+1) # 몇 초 후에 감염되는지 저장
dy[c] = 0 # 감염원(c)은 0초 후에 감염
q = [(0, c)]
while q:
timePassed, infectedCp = heapq.heappop(q)
if dy[infectedCp] < timePassed:
continue
for s, a in data[infectedCp]:
if dy[a] > s + timePassed:
dy[a] = s + timePassed
heapq.heappush(q, (s+timePassed, a))
time = -1
nCp = 0
for i in range(1, n+1):
if dy[i] != 100000000:
time = max(time, dy[i])
nCp += 1
print(nCp, time)
'코딩 테스트' 카테고리의 다른 글
| [백준] 19942 다이어트 (0) | 2021.01.19 |
|---|---|
| [백준] 거스름돈 (0) | 2021.01.19 |
| 11번 테스트 케이스 , 조이스틱 문제 (코딩 기출문제풀이) (0) | 2021.01.12 |
| [백준][파이썬] 9251, LCS (0) | 2021.01.07 |
| [파이썬][백준] 2810번 컵홀더 (0) | 2021.01.07 |